
Text Classification (Lazy Way 😪)
 First of all, I will start with some questions for you:
First of all, I will start with some questions for you:
- Are you the person in charge of managing app development?
- Do you have many error reports on your apps?
- Do you find it difficult to prioritize which ones should be fixed first?
- Do you find it difficult to choose which team should fix the issue?
- Are you curious about how I deal with that?
If most of your answers are “yes”, this might offer you an option. Of course, we all know that in app development, we will face a lot of issues. Sometimes, we spend most of our time fixing non-critical issues rather than focusing on those that might cause the system to collapse. It’s not a big deal if they collapse the development environment, but if it happens in production, you will need an extra shot of coffee. I will show you how I classify issues from just a warning to an emergency alert. I also classify issues to help choose which team is responsible for fixing them.
Let’s Get Started!
I will train a model that receives text input, which will return error severity, and another model that returns stack group. To create the models, we need training data, and by the grace of God, there are some APIs from Stack Exchange that we can access freely. You can try them here. I filtered any title that contains the word ‘error’ and has a tag between ['api', 'database', 'sql', 'nosql', 'frontend', 'backend', 'network', 'docker', 'pipeline', 'devops', 'sre', 'model', 'deployment', 'mobile', 'cloud', 'server', 'ml']. I fetched 25 pages of Stack Overflow questions for every tag on that list. You can read my scraper script here.
While waiting for the scraper to do its job, I realized that…
I Have a Problem
To classify something, that means we need at least one target. So far, I already got 12000+ row of StackOverflow questions and I don’t have energy to label every each of it. After few days of thinking about what I should do, I got my eureka moment! I decided to group the questions into some of topic group. For every tags, I grouped them into 20 topics. I used Latent Dirichlet Allocation (LDA) method by using TruncatedSVD in sklearn library. You can read my topic grouping script here.
Then I manually labeling every topic by class number like list below:
- Warning: A condition might warrant attention
- Error: Minor error, quick to fix
- Critical: A critical error, some features may not working
- Alert: Immidiate action may be required, unstable
- Emergency: The system is stop running
from 12000+ records now i just have to label 300+ topics. Instead of a boring week, i got 15 minutes of fun and exciting task.

Now What?
Now I have to put label in topics into every question row. For every question that contain most of the word in topic, they will get the same label as topic. You can see example on table below. Here is the script.

Then I split the dataframe into 2 groups, for data train and data test. I choose 80% for data train and 20% for data test. I make sure that data test contain exact number of category. This will help me know model performance more accurately.
BERT But Cheaper
I want to use the BERT model because it tends to care about the text context (Masked Language Model). For example, let’s take the following words:
- Since my dog died, I’ve been feeling blue.
- There were swallows in the cloudless blue sky.
The word “blue” means very different things in each sentence. By using BERT, it can be represented with a different embedding.
BERT is also built on top of the Transformer architecture, a neural network architecture family that can transform into cars. It means the model will give attention to the relation between each word in an input sequence. Consider the sentence:
- Since my dog died, I’ve been feeling blue, and now I miss him so much
The word “him” is associated with “my dog,” and Transformer knows that as well. So, the Transformer has a better encoding method than the traditional one.
After some consideration (I don’t have enough GPU power to handle BERT), I found ALBERT: A Lite BERT. It uses two parameter-reduction techniques, so it has lower memory consumption and higher training speed. I’m happy, yay!
Let’s Train It Now, Baby!
I trained the model using PyTorch, and for GPU computation, I used CUDA. I used cross-entropy as the loss function and Adam as the optimizer. The maximum encoding size, in my case, was 64. My GPU didn’t have enough memory to handle anything beyond that number. I trained the model for five epochs, with each iteration taking around three minutes. You can access my training code for severity classification here and for stack group classification here.
The outcome of the training was a severity classification model with 70% accuracy and a stack group classification model with 82% accuracy.
If you want to evaluate its performance, one useful tool is a confusion matrix. A confusion matrix displays the number of true positives, true negatives, false positives, and false negatives for each class in your model. This information can help you better understand how well your model is performing and identify areas for improvement. Example code here
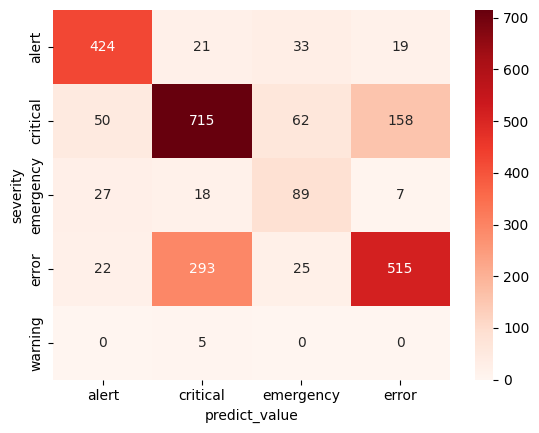
We can read it as: 715 critical errors can be predicted correctly by severity model. As we can see, we need more question data about emergency and warning.
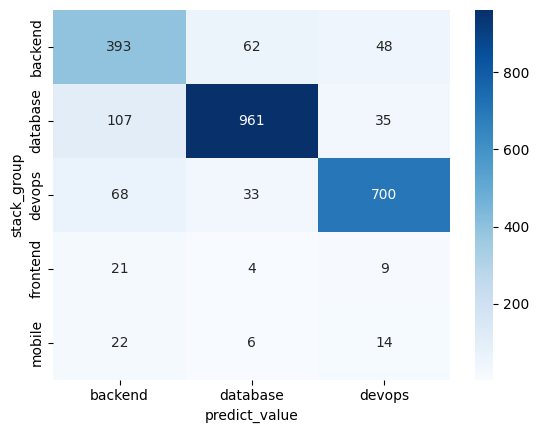
We can read it as: 961 database stack group can be predicted correctly by stack group model. We need more question data about frontend and mobile.
Deploy
We can deploy this model via API so that other teams can use it. For quick development and testing, I used FastAPI. Check it out here
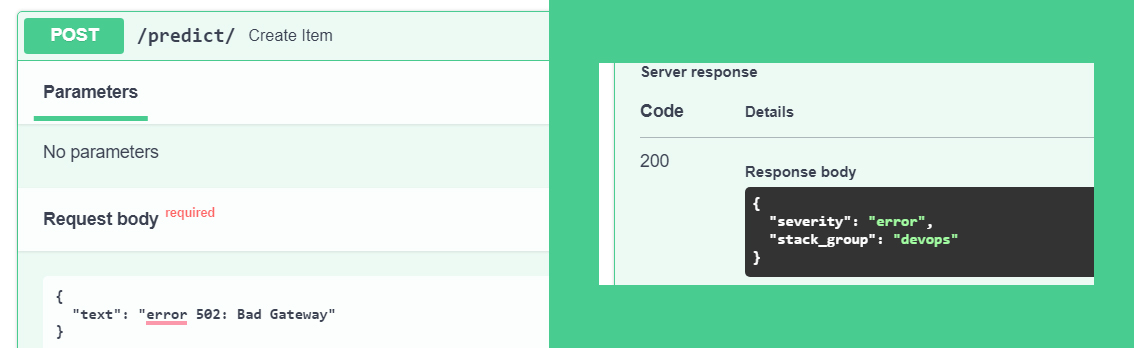
Hope this help :)